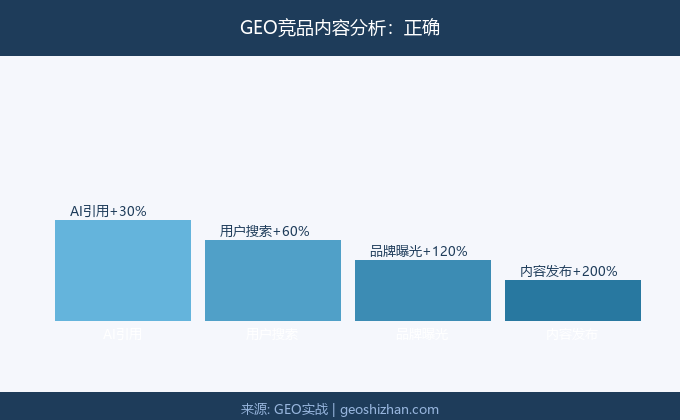
GEO需要持续输出大量内容,但很多企业和个人的资源是有限的。如何在有限资源下最大化内容效果?答案是内容矩阵规划。本文分享如何科学规划GEO内容矩阵。
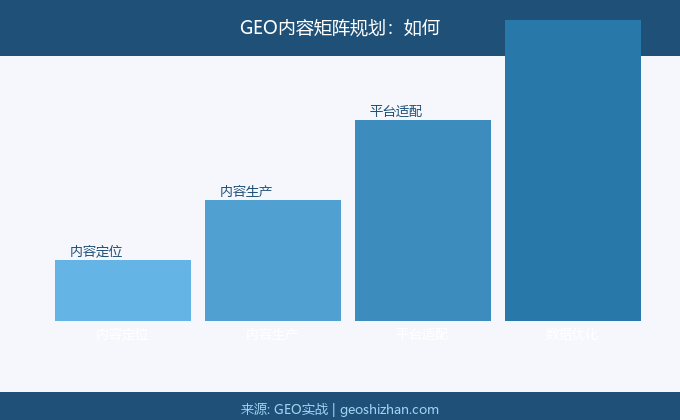
一、什么是内容矩阵
内容矩阵是指围绕核心定位,把不同类型、不同深度、不同角度的内容组合起来,形成互相支撑的系统。
好的内容矩阵能让不同内容互相引流、互相增强。用户在某篇内容中被吸引,会去看其他内容;AI在某个主题下搜索,更容易找到你的内容体系。
做内容矩阵而不是做单一内容,是GEO规模化的关键。
二、内容矩阵的四个层次
内容矩阵一般分为四个层次:
第一层是旗舰内容。这是你的核心作品,通常是深度长文或系列文章,代表你对某个领域的最高水平。旗舰内容是用户记住你的关键。
第二层是常规内容。这是定期发布的常规文章,保持更新频率,覆盖核心关键词。常规内容是流量和引用的基础。
第三层是工具内容。这是指南、清单、教程等实用性内容。工具内容被用户收藏和分享的概率高,是获取长期引用的利器。
第四层是互动内容。这是问答、讨论等互动性内容。互动内容能增加用户粘性,也是收集用户需求的好方式。
三、如何规划内容矩阵
规划内容矩阵的步骤:
步骤一是明确核心定位。找到自己最核心的那个主题,围绕这个主题来规划所有内容。
步骤二是拆解核心主题。把核心主题拆成多个子主题,每个子主题规划若干内容。
步骤三是确定内容类型。不同子主题适合不同类型的内容,根据用户需求选择合适的类型。
步骤四是制定发布计划。确定每个内容的发布时间、负责人、状态。
步骤五是预留灵活空间。计划赶不上变化,要预留一些机动内容名额,用于捕捉热点或填补空缺。
四、内容日历的建立
内容矩阵需要通过内容日历来落地执行。
内容日历的核心要素:发布时间、内容主题、内容类型、负责人、状态。
建议用多维表格来管理内容日历,方便多人协作和状态跟踪。
发布频率建议:旗舰内容每月一到两篇;常规内容每周一到两篇;工具内容和互动内容根据资源情况灵活安排。
五、资源分配的原则
资源有限时,优先把资源放在哪里?
优先一:优先旗舰内容。旗舰内容是内容的核心,是用户记住你的关键,值得投入更多资源。
优先二:优先用户最关心的话题。通过和用户沟通、分析数据,找到用户最关心的话题,集中资源做这些话题。
优先三:优先差异化内容。竞争激烈的话题投入产出比不一定高,选择相对蓝海的领域优先突破。
优先四:优先可持续的话题。选择能持续产出的话题,避免做完一个话题就没内容可写了。
六、内容矩阵的迭代优化
内容矩阵不是一成不变的,需要持续迭代优化。
迭代信号:某个话题持续没有效果;用户需求发生了变化;市场上出现了新的机会。
迭代方法:定期回顾内容矩阵的数据表现,淘汰效果差的话题,增加新的话题方向。
好的内容矩阵是动态演进的,在保持核心定位稳定的前提下,持续微调和优化。